Drei Dinge, die Sie über Reinforcement Learning wissen sollten
Von Emmanouil Tzorakoleftherakis, MathWorks
Wenn Sie technische Nachrichten verfolgen, haben Sie wahrscheinlich bereits gelesen, dass KI-Programme, die mit Reinforcement Learning trainiert wurden, menschliche Spieler in Brettspielen wie Go und Schach sowie in Videospielen schlagen. Als Ingenieure, Wissenschaftler oder Forscher möchten Sie möglicherweise die Vorteile dieser neuen, wachsenden Technologie nutzen, aber wie finden Sie den Einstieg? Am besten finden Sie zuerst heraus, was das Konzept ist, wie Sie es umsetzen können und ob es der richtige Ansatz für das jeweilige Problem ist.
Vereinfacht gesagt ist Reinforcement Learning eine Form von Machine Learning, mit der schwierige Entscheidungsprobleme gelöst werden können. Um den Nutzen des Konzepts wirklich zu verstehen, müssen wir jedoch drei Schlüsselfragen beantworten:
- Was ist Reinforcement Learning, und warum sollte ich es für die Lösung meines Problems in Betracht ziehen?
- Wann ist Reinforcement Learning der richtige Ansatz?
- Welchen Workflow sollte ich nutzen, um mein Reinforcement-Learning-Problem zu lösen?
Was ist Reinforcement Learning?
Reinforcement Learning ist eine Form von Machine Learning, mit der ein Computer lernt, eine Aufgabe durch wiederholte Trial-and-Error-Interaktionen mit einer dynamischen Umgebung auszuführen. Mit diesem Lernansatz kann der Computer eine Reihe von Entscheidungen treffen, mit denen eine Belohnungsmetrik für die Aufgabe maximiert wird, ohne dass ein Mensch eingreift und ohne dass der Computer explizit für diese Aufgabe programmiert ist.
Um das Reinforcement Learning besser zu verstehen, sehen wir uns eine analoge Situation im Alltagsleben an. Abbildung 1 zeigt schematisch, wie ein Hund durch Belohnung lernt.
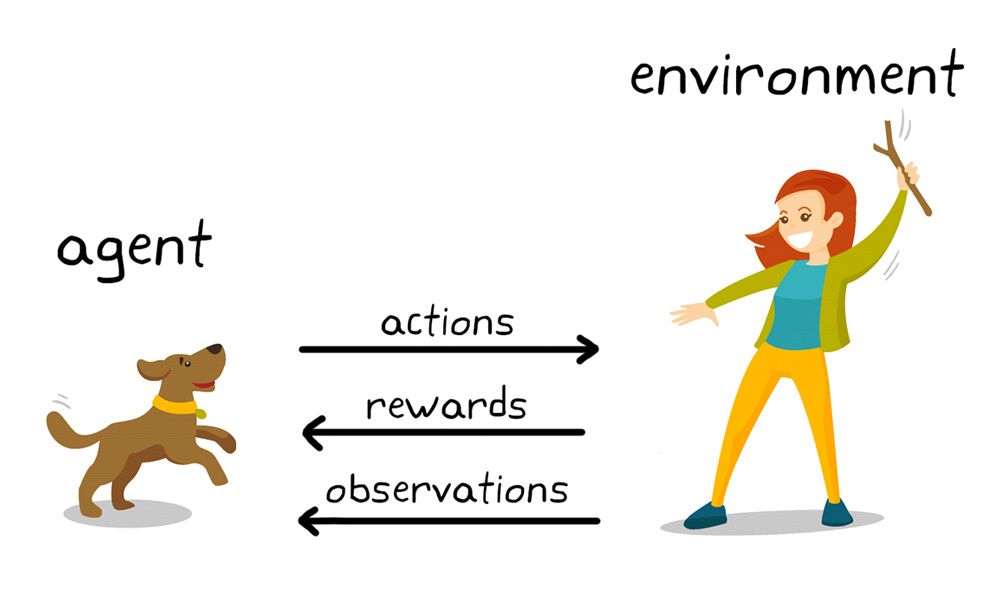
Abbildung 1. Verstärkendes Lernen in der Hundeerziehung.
Ziel des verstärkenden Lernens ist es in diesem Fall, den Hund (den Agenten) so zu trainieren, dass er eine Aufgabe in einer Umgebung erfüllt, zu der sowohl die physische Umgebung des Hundes als auch die Trainerin gehört. Zuerst gibt die Trainerin einen Befehl oder Hinweis, den der Hund beobachtet (Beobachtung). Darauf reagiert der Hund mit einer Aktion. Wenn die Aktion dem gewünschten Verhalten nahekommt, gibt die Trainerin wahrscheinlich eine Belohnung, wie ein Leckerchen oder ein Spielzeug; andernfalls gibt sie keine Belohnung oder eine negative Reaktion. Zu Beginn des Trainings wird der Hund wahrscheinlich mehr Aktionen aufs Geratewohl durchführen, wie z. B. eine Rolle, wenn der Befehl „Sitz“ lautet, da er versucht, bestimmte Beobachtungen mit Aktionen und Belohnungen in Verbindung zu bringen. Diese Verbindung oder Zuordnung zwischen Beobachtungen und Aktionen wird als Strategie bezeichnet. Aus der Perspektive des Hundes würde der ideale Fall darin bestehen, dass er auf jeden Hinweis richtig reagiert, um so viele Leckerchen zu erhalten wie möglich. Das verstärkende Lernen besteht also darin, die Strategie des Hundes auf die Verhaltensweisen hin zu optimieren, mit denen er seine Belohnung maximiert. Nach Abschluss des Trainings sollte der Hund in der Lage sein, seinen Besitzer zu beobachten und die richtige Aktion durchzuführen – z. B. sich beim Befehl „Sitz“ zu setzen –, indem er die selbst entwickelte interne Strategie anwendet. Zu diesem Zeitpunkt sind Leckerchen willkommen, sollten aber nicht notwendig sein (theoretisch gesehen!).
Betrachten Sie ausgehend vom Beispiel der Hundeerziehung die Aufgabe, ein Fahrzeug mit einem automatisierten Fahrsystem zu parken (Abbildung 2). Ziel dieser Aufgabe ist es, dass der Fahrzeugcomputer (Agent) das Fahrzeug in der richtigen Parklücke und in der richtigen Richtung parkt. Wie im Fall der Hundeerziehung ist die Umgebung auch hier alles, was den Agenten umgibt. Dazu können die Dynamik des Fahrzeugs, andere Fahrzeuge in der Nähe, die Wetterbedingungen usw. gehören. Während des Trainings verwendet der Agent Messwerte von Sensoren wie Kameras, GPS und LiDAR (Beobachtungen), um Lenk-, Brems- und Beschleunigungsbefehle (Aktionen) zu erzeugen. Um zu lernen, wie er aus den Beobachtungen die richtigen Aktionen erzeugen kann (Strategieoptimierung), versucht der Agent mit einem Trial-and-Error-Prozess immer wieder, das Fahrzeug zu parken. Es kann ein Belohnungssignal gegeben werden, um die Güte eines Versuchs zu bewerten und den Lernprozess zu steuern.

Abbildung 2. Reinforcement Learning beim autonomen Parken.
Im Beispiel der Hundeerziehung findet das Training im Gehirn des Hundes statt. Im Beispiel des autonomen Parkens wird es durch einen Trainingsalgorithmus überwacht. Der Trainingsalgorithmus optimiert die Strategie des Agenten anhand der erfassten Sensormesswerte, der Aktionen und der Belohnungen. Nach Abschluss des Trainings sollte der Computer des Fahrzeugs in der Lage sein, es nur anhand der optimierten Strategie und der Sensormesswerte zu parken.
Wann ist Reinforcement Learning der richtige Ansatz?
Es wurden bereits viele Trainingsalgorithmen für Reinforcement Learning entwickelt. Trainingsalgorithmen sind nicht Thema dieses Artikels, aber es ist erwähnenswert, dass einige der beliebtesten auf Strategien beruhen, die mit tiefen neuronalen Netzen gelernt werden. Der größte Vorteil neuronaler Netze besteht darin, dass sie sehr komplexe Verhaltensweisen darstellen können. Dies ermöglicht den Einsatz von Reinforcement Learning für Anwendungen, die mit anderen Methoden, einschließlich herkömmlicher Algorithmen, unlösbar oder sehr schwierig wären. So kann beispielsweise beim autonomen Fahren ein neuronales Netz den Fahrer ersetzen und entscheiden, wie das Lenkrad gedreht werden soll, indem es gleichzeitig Eingangssignale von mehreren Sensoren betrachtet, wie Kamera-Frames und LiDAR-Messungen (End-to-End-Lösung). Ohne neuronale Netze würde das Problem normalerweise in kleinere Teile zerlegt: ein Modul, das Eingangssignale von der Kamera analysiert, um nützliche Merkmale zu identifizieren, ein weiteres Modul, das die LiDAR-Messwerte filtert, möglicherweise eine Komponente, die die gesamte Umgebung des Fahrzeugs durch Zusammenführen der Sensorausgaben darstellen soll, ein „Fahrer“-Modul und mehr. End-to-End-Lösungen sind jedoch nicht nur nützlich, sondern haben auch einige Nachteile.
Die Strategie eines trainierten tiefen neuronalen Netzes wird oft als „Black Box“ behandelt. Dies bedeutet, dass die interne Struktur des neuronalen Netzes so komplex ist – häufig mit Millionen Parametern –, dass es fast unmöglich ist, seine Entscheidungen zu verstehen, zu erklären und zu bewerten (linke Seite von Abbildung 3). Daher ist es schwierig, die Leistung von Strategien neuronaler Netze formal zu garantieren. Betrachten Sie es so: Auch wenn Sie Ihr Haustier erziehen, wird es Ihre Befehle ab und zu einfach nicht hören.

Abbildung 3. Einige der Herausforderungen des Reinforcement Learning.
Beachten Sie außerdem, dass Reinforcement Learning nicht stichprobeneffizient ist. Das bedeutet, dass in der Regel viel Training erforderlich ist, um eine akzeptable Leistung zu erreichen. Beispielsweise wurde AlphaGo, das erste Computerprogramm, das einen Weltmeister im Go-Spiel besiegt hat, einige Tage lang pausenlos trainiert, indem es Millionen von Spielen spielte und damit so viel Wissen sammelte wie ein Mensch in Tausenden von Jahren. Selbst für relativ einfache Anwendungen kann das Training Minuten, Stunden oder Tage dauern. Schließlich kann die richtige Vorbereitung des Problems schwierig sein: Viele Entwurfsentscheidungen müssen getroffen werden. Sie zu optimieren, kann einige Iterationen erfordern (rechte Seite von Abbildung 3). Zu diesen Entscheidungen gehören beispielsweise die Auswahl der passenden Architektur für die neuronalen Netze, die Feinabstimmung von Hyperparametern und die Gestaltung des Belohnungssignals.
Kurz gesagt: Wenn Sie an einem zeit- oder sicherheitskritischen Projekt arbeiten, das Sie auch mit anderen herkömmlichen Methoden angehen können, ist Reinforcement Learning vielleicht nicht das, was Sie zuerst versuchen sollten. Wenn das nicht der Fall ist, probieren Sie es aus!
Workflow für Reinforcement Learning
Der allgemeine Workflow für das Training eines Agenten durch Reinforcement Learning umfasst die folgenden Schritte (Abbildung 4).

Abbildung 4. Workflow für Reinforcement Learning.
- Erstellen der Umgebung
Zunächst müssen Sie die Umgebung definieren, in der der Agent arbeitet, einschließlich der Schnittstelle zwischen dem Agenten und der Umgebung. Die Umgebung kann entweder ein Simulationsmodell oder ein reales physikalisches System sein. Simulierte Umgebungen sind in der Regel gut für die ersten Schritte, da sie sicherer sind (echte Hardware ist teuer) und Experimente ermöglichen. - Definieren der Belohnung
Geben Sie als Nächstes das Belohnungssignal an, mit dem der Agent seine Leistung in Bezug auf die Aufgabenziele misst, und legen Sie fest, wie dieses Signal aus der Umgebung berechnet wird. Die Gestaltung der Belohnung kann schwierig sein. Sie zu optimieren, kann einige Iterationen erfordern. - Erstellen des Agenten
In diesem Schritt erstellen Sie den Agenten. Der Agent besteht aus der Strategie und dem Trainingsalgorithmus (siehe Abbildung 2). Gehen Sie daher wie folgt vor:- Wählen Sie eine Möglichkeit, die Strategie darzustellen (z. B. durch neuronale Netze oder Look-Up-Tables).
- Wählen Sie den richtigen Trainingsalgorithmus aus. Unterschiedliche Darstellungen sind oft mit bestimmten Kategorien von Trainingsalgorithmen verbunden. Im Allgemeinen basieren die meisten modernen Algorithmen auf neuronalen Netzen, da diese gute Kandidaten für große Zustands-/Aktionsräume und komplexe Probleme sind.
- Trainieren und Überprüfen des Agenten
Legen Sie Trainingsoptionen fest (z. B. Stoppkriterien) und trainieren Sie den Agenten, um die Strategie zu optimieren. Überprüfen Sie die trainierte Strategie nach Beendigung des Trainings. Das Training kann je nach Anwendung Minuten bis Tage dauern. Für komplexe Anwendungen kann das Training auf mehrere CPUs, GPUs und Computercluster parallelisiert werden, um es zu beschleunigen. - Bereitstellen der Strategie
Stellen Sie die trainierte Strategie z. B. in Form von generiertem C/C++- oder CUDA-Code bereit. Sie müssen sich an diesem Punkt keine Sorgen um Agenten und Trainingsalgorithmen machen – die Strategie ist ein eigenständiges Entscheidungssystem!
Das Training eines Agenten durch Reinforcement Learning ist ein iterativer Prozess. Für Entscheidungen und Ergebnisse in späteren Phasen kann es notwendig sein, zu einer früheren Phase des Lern-Workflows zurückzukehren. Wenn der Trainingsprozess beispielsweise nicht innerhalb eines angemessenen Zeitraums zu einer optimalen Strategie konvergiert, müssen Sie möglicherweise einige der folgenden Elemente verändern, bevor Sie den Agenten erneut trainieren:
- Trainingseinstellungen
- Konfiguration des Lernalgorithmus
- Strategie
- Definition des Belohnungssignals
- Aktions- und Beobachtungssignale
- Umgebungsdynamik
Zusammenfassung
Heute können Sie mit Tools wie der Reinforcement Learning Toolbox (Abbildung 5) Regler und Entscheidungsalgorithmen für komplexe Systeme wie Roboter und autonome Anlagen schnell trainieren und implementieren.

Abbildung 5. Trainieren eines gehenden Roboters mit der Reinforcement Learning Toolbox.
Stellen Sie sich unabhängig von der Wahl des Tools folgende Frage, bevor Sie sich für Reinforcement Learning entscheiden: „Ist angesichts der Zeit und Ressourcen, die ich für dieses Projekt habe, Reinforcement Learning der richtige Ansatz für mich?“
Veröffentlicht 2020
Eingesetzte Produkte
Weitere Informationen
-
Reinforcement Learning mit MATLAB and Simulink - Überblick
-
Reinforcement Learning - Video-Reihe